第一条:
CFD计算加速比在sci里面很常见,但在岳子之前,没有服务器厂家做服务器,会把CFD加速比当做一个标准… 一些厂家认为3个节点以上速度上不去是正常的。但是在岳子这,按照做sci的严谨态度,业内首次提出集群要以加速比为出货标准!
机架式CFD加特林

致尊贵的梅赛德斯CFD大佬
Right now,此时此刻,我们做CFD机架式服务器信手拈来。
在我们这里,我掐个响指,就能轻松调用3000核。一顿饭的功夫,2亿网格点的DNS就能算一万步。
经过时间的洗礼,CFD加特林出货已经工厂流水线作业。分工明确,各司其职。咔咔咔的就是往外出。我李东岳就是公司一把手,我专注学术,但我同样很灵活。合作讲究的是共赢。在小行业内还讲究信誉。CFD加特林绝对是我这面的标杆产品,好评如潮。
大佬经常是先来10台,半年后再来10台。从此在超算中心这一条路上,1000核1000核的往上堆,越走越远,彻底无法回头。
我在国外我自己也是远程用这个。要说刚开始的半年,那就是摸索。此时此刻,机架式CFD服务器的各种问题都已经摸透。砸成灰我都能看出毛病在哪里。在CFD性能调优这一方面,必须拿捏!
搞CFD的,最需要的就是服务器。服务器就是CFD大佬的手中刀。一套好的服务器,大佬的仕途就犹如龙得水,虎归山。
什么才是有排面?国家重点实验室,几十人上百人的大课题组,必须要有一套上千核心的CFD服务器。4节点CFD加特林就是低配版本的奔驰E300。10节点的CFD加特林就是23款的奔驰S。20节点1280核的CFD加特林就是梅赛德斯-迈巴赫!
只有CFD加特林,才配得上CFD大佬的地位,上千核的CFD加特林才有排面。其他的都是弟弟!
尊贵的梅赛德斯CFD大佬,请安排小弟与我助理对接,CFD加特林才是大佬的最终归宿,加特林才匹配大佬的身份!
加速比
加速比:多个机器连起来计算,比单个机器快多少倍。加速比很重要:80%的人,不知道机架式CFD服务器加速比的概念。更别提自己购买的服务器,能不能到线性加速比。
线性加速比:n个机器计算比单机快n倍。
超线性加速比:n个机器计算比单机快大于n倍。
塔式服务器由于架构原因,注定达不到线性加速比,更别提超线性加速比。因此塔式服务器128核心没有意义!最好还是当做算例调试用。上亿网格点,你的唯一选择就是机架式服务器。我们的机架式服务器称之为CFD加特林。CFD加特林的终极目标是超线性加速比,最低是线性加速比。下图是我们采用OpenFOAM,2000万网格,测试的14节点896核心的并行效果,已经达到了超线性加速比:

Warning
需要强调的是,其他大厂交付完全不保证加速比,甚至连多节点运算也不会给安装。
更多的数据可以参考我们提倡的性能测试CFD标准算例。总而言之,我们这面的CFD加特林,绝对可以做到线性加速比。在某些情况下,还可以出现超线性加速比。
这不仅仅是硬件
第二条:
CFD机架式服务器不是纯硬件!试想:硬件发货后,需要装CFD软件么?需要调试加速比么?需要学习怎么使用么?半年后系统崩溃了怎么办?节点down了怎么办?需要新装软件怎么办?
有很多人以为,机架式服务器可以当做纯硬件,找几家供应商,报个价,找个最低的就完了。这真是大错特错。
CFD机架式服务器在日常使用中,需要多机器互联,需要任务分配。我们出了几十套机架式服务器,在使用过程中,会发现80%的客户,不会装软件、有时候网络还被黑、有时候系统时间改错了、有时候驱动搞坏了、有时候OpenFOAM莫名其妙的卡死了、Fluent起不来了、有时候系统彻底崩溃了黑屏了进不去了。这些是不是都需要处理?
我们的技术人员,也懂CFD,也懂linux。你们可以问一下大厂,他们不可能在CFD方面给你们调试。甚至连系统都不会装,集群更不会给你们配。谈何线性加速比?
我知道大厂有客服,大家可以想一下,400电话问客服,能解决CFD问题么?能解决内存泄露问题么?能解决节点并行计算配置问题么?
我们在交货的时候,会详细的手把手讲解如何跑CFD软件;
后期在使用过程中,如果有基本的CFD问题,也可以咨询;
当然这里面有个度。肯定不是客户买个服务器,我这面24小时为你们解答各种CFD问题。这里面存在一个度。简单问题,还是建议自己搜一搜。处理不了的,可以联系我这面专家问一问。咱这面的专家,绝对是懂CFD、懂机架式服务器、懂linux的高手。技术方面,绝对是一流的。
Warning
大厂的交付:纯硬件,自己装系统,自己配集群。后期有400电话客服,但问了基本也不懂;
我么的交付:硬件+系统+线性加速比。后期可以微信联系我方专家。门清;
标准配置
塔式服务器在同样的预算下,可以选出最强配置。但是机架式服务器不一样,机架式服务器很多参数都可调,比如
单节点核心数;
节点数量;
同样的性能,如3000万网格跑到20秒,可以采用多种方案来实现,可以达到同样的性能,但价格不一样。咱这面大体主推3个型号,如果没有明确的概念,可做定制:
配置 |
DMC-2025 |
DMC-2026 |
DMC-2023a |
|---|---|---|---|
特性 |
性价比高 |
单节点性能极强 |
2025年主推 |
每计算点 |
96核/256G内存 |
64核/256G内存 |
64核/256G内存 |
存储 |
10T |
10T |
10T |
外设 |
ETH交换机等 |
ETH交换机等 |
ETH交换机等 |
实测性能 |
单节点85秒 |
单节点34秒 |
单节点64秒 |
计算节点 |
每节点4万 |
每节点16万 |
每节点5.7万 |
管理节点 |
16核 0.7万 |
16核 0.7万 |
16核 0.7万 |
最低配 |
4节点+1管理点 |
3节点+1管理点 |
4节点+1管理点 |
上述报价所有全包(运输+安装+培训+发票)。售后条款请参考做人与售后.
Warning
请不要简单的追求单节点多核心。同样的性能下,核心越少越好。一再强调,一套4节点每节点64核的机架式,要比1节点256核心的塔式要快得多!
很多人会说,我们这个机架式的配置太简单了,想要详细的配置。比如下图这种。下图是黛儿一个5节点80万的服务器。如图:
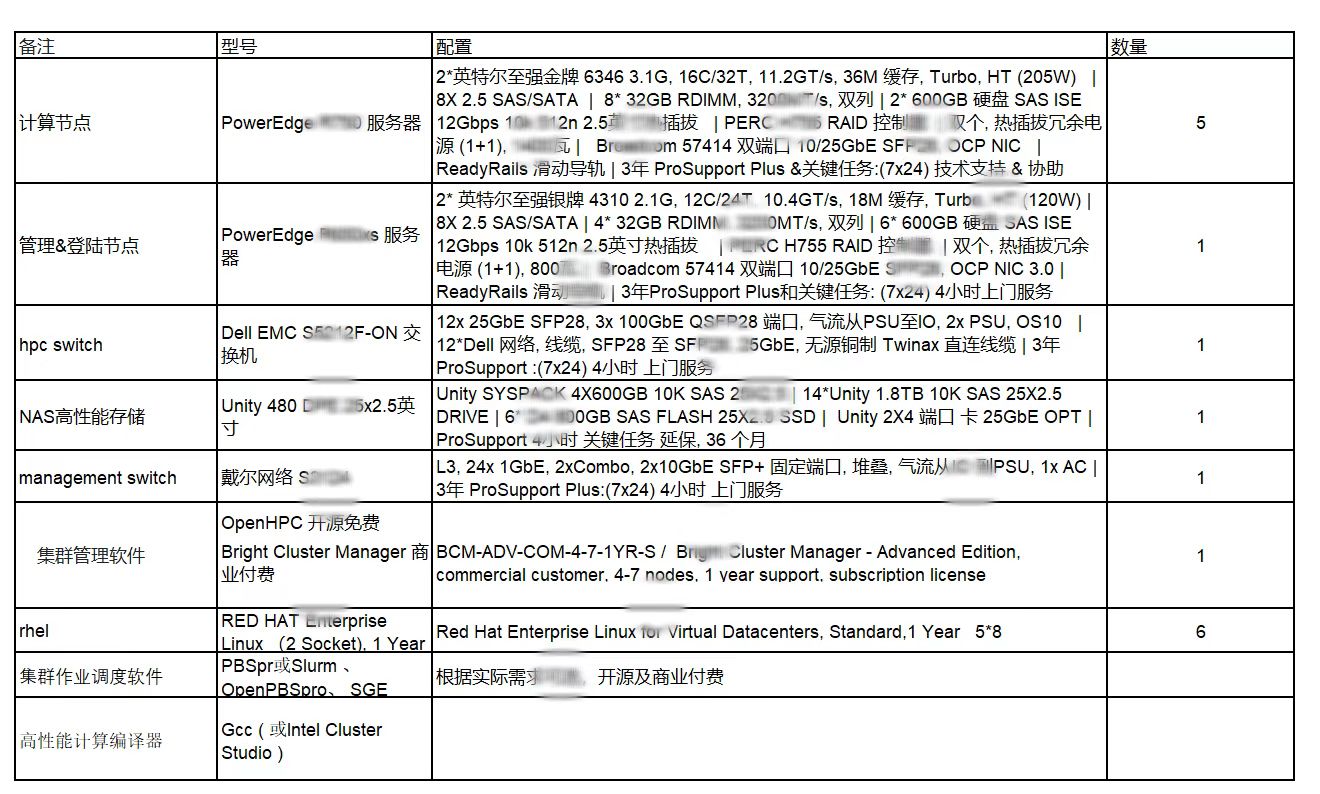
简要评述以下:
上面这些论七八糟的参数,我们也可以写,但是啥用没有,徒增工作量。就跟大家做科研一样。无意义的文字工作大家都不爱做。
我们的4节点服务器,跑CFD,比上面的5节点服务器要快50%以上。因为我们测试过这个配置;
在CFD性能快50%的情况下,价格是黛儿的三分之一!!!
黛儿服务器上述配置不含有CFD软件配置服务,更别提线性加速比!!
一个典型的10节点服务器的交付主要包含:
10个计算节点:每节点32核心-64核心,每节点128G内存-256G内存,不需显卡。
1个管理节点:每节点32核心-64核心,每节点128G内存,2T系统盘,不需显卡。
网络交互系统:ETH交换机,若干网卡,若干线缆。
机柜:8节点以下一个机柜,每8个节点一个机柜。
质保:整机三年质保。硬件有问题免费换。
物流安装:运输、现场安装、培训、部署费用。
下图是我们交付的10节点服务器实拍图:


由于机架式服务器货值高,可以把合同分割成多个小额合同,走测试费、会议费等处理。通常我们会备一台4节点现货。如果碰巧有现货。只要到款快,款到即发。
Warning
有人问,这面DM塔式服务器,一台64核,3万元,我拿5台,只有15万元。不都是320核么?错误!一再强调,同核心数机架式,要完爆塔式服务器。 当然,前提是调试出线性的加速比。再比如,4节点128核的机架式,要比单节点128核心的塔式要快得多!
如何购买
购买请发邮件:li.dy@dyfluid.com