版本对应:
本网页讨论的机器学习内容,为特定的机器学习内容(并未与CFD结合)。在《无痛苦NS方程笔记》中, 特定的将CFD与机器学习互相结合起来,无普适性机器学习内容。
ML: PINN代码-耦合ODE (双耦合PDE)
本文尝试使用PINN求解Lotka-Volterra方程。在阅读本文之前,请阅读ML: PINN代码实例-1D槽道流,防止出现不理解跟不上的情况。
Lotka-Volterra方程是2个耦合的ODE,其中不同的参数,可以具有不同的解。在这个链接中,可以自行更改ODE的参数,实时的获得解析解。Lotka-Volterra方程可以表示为
其中\(a_1=5,a_2=6,c_{12}=c_{21}=1\)。用户可以在这个链接中自行调试这些参数,可以发现Lotka-Volterra方程会预测非常不同的结果。
PINN网格划分
在OpenFOAM libtorch环境下,可以通过下面几行来生成网格:
auto mesh = torch::arange(0, 1.9, 0.1).reshape({-1,1});
mesh.set_requires_grad(true);
其中的arrange函数,请参考ML: libtorch张量(二)。
神经网络搭建
在OpenFOAM libtorch环境下,可以通过下述代码搭建神经网络:
class NN
:
public torch::nn::Module
{
torch::nn::Sequential net_;
public:
NN()
{
net_ =
register_module
(
"net",
torch::nn::Sequential
(
torch::nn::Linear(1,10),
torch::nn::Tanh(),
torch::nn::Linear(10,10),
torch::nn::Tanh(),
torch::nn::Linear(10,2)
)
);
}
auto forward(torch::Tensor x)
{
return net_->forward(x);
}
};
其为一个常规的全连接网络,采用Tanh激活函数,每次10个神经元,输入层1个参数,输出层2个参数。
超参数以及自动微分
PINN在训练网络的时候,需要指定梯度下降的方法。这部分理论请参考ML: 手算反向传播与自动微分。具体的,本算例训练50000次,采用Adam梯度更新方法。学习率为0.001。损失计算的方法采用均方差最小化。在OpenFOAM libtorch环境下的代码可以写为
torch::manual_seed(0);
int iter = 1;
int IterationNum = 50000;
double lr = 1e-3;
auto crit = torch::nn::MSELoss();
auto model = std::make_shared<NN>();
auto opti =
std::make_shared<torch::optim::Adam>
(
model->parameters(),
torch::optim::AdamOptions(lr)
);
上述内容均属于常规操作。对于本文的神经网络,可以通过下面的代码进行输出:
auto xy = model->forward(mesh);
auto x = xy.index({torch::indexing::Slice(), 0}).reshape({-1,1});
auto y = xy.index({torch::indexing::Slice(), 1}).reshape({-1,1});
需要注意的是,本文的神经网络输出的为2个参数,因此xytensor的形状为{19,2},其中的19表示网格单元数。其中的index操作,将xy的列元素提取出来,形成单独的x以及y。在此基础上,可以进行自动微分:
auto dxdt =
torch::autograd::grad
(
{x}, {mesh}, {torch::ones_like(x)}, true, true
)[0];
auto dydt =
torch::autograd::grad
(
{y}, {mesh}, {torch::ones_like(y)}, true, true
)[0];
损失
本文的耦合的ODE具有2个方程,为了更好地训练,本文定义3个损失:
方程损失;
边界损失;
数据损失;
方程的损失可以定义为
auto f1 = dxdt - a1*x + c12*x*y;
auto f2 = dydt + a2*y - c21*x*y;
auto loss1 = crit(f1, 0.0*f1);
auto loss2 = crit(f2, 0.0*f2);
初次之外,边界损失可以定义为
auto loss3 = crit(x0, x.index({0}));
auto loss4 = crit(y0, y.index({0}));
其中的index函数可以参考ML: libtorch张量(二)。下面我们定义数据损失:
#include "data.H"
数据损失即为神经网络预测的点与提取的解析解的点的差异。最终有总损失:
auto loss = loss1 + loss3 + loss2 + loss4 + loss5 + loss6;
随后进行训练即可。
运行算例
请首先按照OpenFOAM libtorch tutorial step by step来配置OpenFOAM libtorch环境。也可以在这里下载配置好的虚拟机。本算例的源代码请参考本文文末。
将源代码直接创立一个.C文件后,即可通过wmake来编译。编译后可以进行训练。训练过程的log如下:
dyfluid@dyfluid-virtual-machine:~/source/code/ML/4-lotkaVolterra-coupled$ lotkaVolterra
500 loss = 229.306
1000 loss = 61.6972
1500 loss = 47.0121
2000 loss = 41.3949
2500 loss = 37.382
3000 loss = 34.4413
3500 loss = 31.5408
4000 loss = 15.2306
4500 loss = 10.4132
5000 loss = 8.61934
5500 loss = 7.34001
6000 loss = 6.29833
6500 loss = 5.37021
7000 loss = 4.4909
7500 loss = 3.69553
8000 loss = 3.01945
8500 loss = 2.4769
9000 loss = 2.06165
9500 loss = 1.7428
10000 loss = 1.48779
10500 loss = 1.27579
11000 loss = 1.08665
11500 loss = 0.912517
12000 loss = 0.777866
12500 loss = 0.670766
13000 loss = 0.583666
13500 loss = 0.512146
14000 loss = 0.471097
14500 loss = 0.411536
15000 loss = 0.366413
15500 loss = 0.334259
16000 loss = 0.307333
16500 loss = 0.284608
17000 loss = 0.26518
17500 loss = 0.248345
18000 loss = 0.233543
18500 loss = 0.220394
19000 loss = 0.208376
19500 loss = 0.197417
20000 loss = 0.187142
20500 loss = 0.177603
21000 loss = 0.168636
21500 loss = 0.159863
22000 loss = 0.152558
22500 loss = 0.143973
23000 loss = 0.1415
23500 loss = 0.129767
24000 loss = 0.123372
24500 loss = 0.138523
25000 loss = 0.111974
25500 loss = 0.106436
26000 loss = 0.10646
26500 loss = 0.105635
27000 loss = 0.0929342
27500 loss = 0.0890507
28000 loss = 0.0854735
28500 loss = 0.0819435
29000 loss = 0.078699
29500 loss = 0.0756077
30000 loss = 0.0841585
30500 loss = 0.0698074
31000 loss = 0.0687944
31500 loss = 0.0667595
32000 loss = 0.0620816
32500 loss = 0.0595187
33000 loss = 0.0570337
33500 loss = 0.0547324
34000 loss = 0.0525469
34500 loss = 0.0503508
35000 loss = 0.0484192
35500 loss = 0.0463215
36000 loss = 0.0444001
36500 loss = 0.0425323
37000 loss = 0.0408346
37500 loss = 0.0390203
38000 loss = 0.0374206
38500 loss = 0.0358038
39000 loss = 0.0343059
39500 loss = 0.0348738
40000 loss = 0.0315029
40500 loss = 0.0302128
41000 loss = 0.0289717
41500 loss = 0.027824
42000 loss = 0.0266658
42500 loss = 0.0256056
43000 loss = 0.024596
43500 loss = 0.0237517
44000 loss = 0.0227224
44500 loss = 0.0218631
45000 loss = 0.0210535
45500 loss = 0.0202801
46000 loss = 0.0196323
46500 loss = 0.0188489
47000 loss = 0.0181904
47500 loss = 0.0175674
48000 loss = 0.016975
48500 loss = 0.0165304
49000 loss = 0.0158832
49500 loss = 0.0153789
50000 loss = 0.0149014
Done!
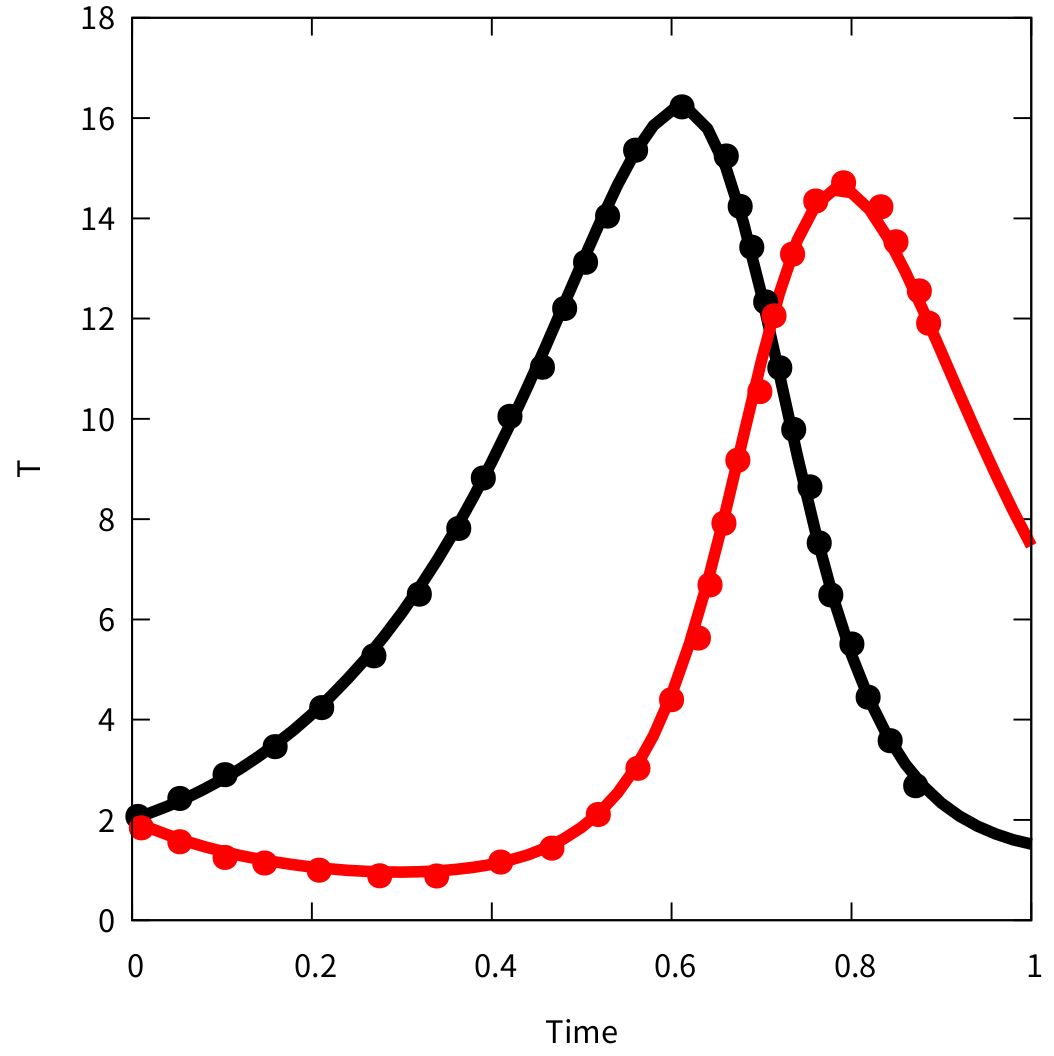
在这里我们将PINN计算的结果(线条)与解析解(圆点)对比,如下图(通过gnuplot绘制):
源代码:
C文件:
#include <torch/torch.h>
using namespace std;
class NN
:
public torch::nn::Module
{
torch::nn::Sequential net_;
public:
NN()
{
net_ =
register_module
(
"net",
torch::nn::Sequential
(
torch::nn::Linear(1,10),
torch::nn::Tanh(),
torch::nn::Linear(10,10),
torch::nn::Tanh(),
torch::nn::Linear(10,2)
)
);
}
auto forward(torch::Tensor x)
{
return net_->forward(x);
}
};
int main()
{
torch::manual_seed(0);
int iter = 1;
int IterationNum = 50000;
double lr = 1e-3;
auto crit = torch::nn::MSELoss();
auto model = std::make_shared<NN>();
auto opti =
std::make_shared<torch::optim::Adam>
(
model->parameters(),
torch::optim::AdamOptions(lr)
);
double a1 = 5.0;
double a2 = 6.0;
double c12 = 1.0;
double c21 = 1.0;
auto x0 = torch::full({1}, 2.0);
auto y0 = torch::full({1}, 2.0);
auto mesh = torch::arange(0, 1.9, 0.02).reshape({-1,1});
mesh.set_requires_grad(true);
for (int i = 0; i < IterationNum; i++)
{
opti->zero_grad();
auto xy = model->forward(mesh);
auto x = xy.index({torch::indexing::Slice(), 0}).reshape({-1,1});
auto y = xy.index({torch::indexing::Slice(), 1}).reshape({-1,1});
auto dxdt =
torch::autograd::grad
(
{x}, {mesh}, {torch::ones_like(x)}, true, true
)[0];
auto dydt =
torch::autograd::grad
(
{y}, {mesh}, {torch::ones_like(y)}, true, true
)[0];
auto f1 = dxdt - a1*x + c12*x*y;
auto f2 = dydt + a2*y - c21*x*y;
#include "data.H"
auto loss1 = crit(f1, 0.0*f1);
auto loss2 = crit(f2, 0.0*f2);
auto loss3 = crit(x0, x.index({0}));
auto loss4 = crit(y0, y.index({0}));
auto loss = loss1 + loss3 + loss2 + loss4 + loss5 + loss6;
loss.backward();
opti->step();
if (iter % 500 == 0)
{
cout<< iter << " loss = " << loss.item<double>() << endl;
auto meshxy = torch::cat({mesh,x,y}, 1);
std::ofstream filex("results");
filex << meshxy << "\n";
filex.close();
}
iter++;
}
std::cout<< "Done!" << std::endl;
return 0;
}
data.H:
auto dataPox = torch::tensor({{0.55991}, {0.77715}});
auto train1 = model->forward(dataPox);
auto xtrain = train1.index({torch::indexing::Slice(), 0}).unsqueeze(1);
auto dataX = torch::tensor({{15.35796}, {6.48939}});
auto dataPoy = torch::tensor({{0.65818}, {0.88577}});
auto dataY = torch::tensor({{7.91881}, {11.90934}});
auto train2 = model->forward(dataPoy);
auto ytrain = train2.index({torch::indexing::Slice(), 1}).unsqueeze(1);
auto loss5 = crit(xtrain, dataX);
auto loss6 = crit(ytrain, dataY);