版本对应:
本网页讨论的机器学习内容,为特定的机器学习内容(并未与CFD结合)。在《无痛苦NS方程笔记》中, 特定的将CFD与机器学习互相结合起来,无普适性机器学习内容。
ML: 强化学习之深度Q网络
在阅读本文之前,请阅读《无痛苦NS方程笔记》中的监督学习的数学算法一节。
各种监督学习,用白话来讲,就是寻找拟合函数。最简单的情况,甚至可以用excel软件来寻找拟合函数。监督学习就是用计算机寻找多分段的拟合函数。现在来看好像没有什么特别复杂难以理解的地方。好像也没有展现“机器自我学习”这个情况。一般般而已。
在强化学习里面,用户会感觉到机器是在进行某种自我学习,学习某种经验,然后去寻找特定情况下的最优解决方案。与监督学习最大的不同点在于强化学习不需要提供标签。强化学习的某种神秘的力量会自我判断当前所做的选的是错误的还是正确的。接下来我们来看一下强化学习的普适性概念。
几乎所有的强化学习的算法提出,包括各大教材讲义针对强化学习的介绍,都是基于玩电子游戏这个应用而进行的。因此通过玩电子游戏来介绍强化学习的基本概念会非常的通俗易懂。强化学习与CFD的结合,请参考《无痛苦NS方程笔记》。
人脑识别的最优过程
如下图显示,假设我们在玩一个游戏,这个游戏需要让里面CFD中文网的猫logo,通过最短的路线去走到dyfluid的logo上。如果是人在玩游戏,那么需要人来操作是左走还是右走。我们想通过计算机去玩游戏,那么操纵左走还是右走的就是计算机。

在强化学习里面,操纵左走还是右走的这么个东西,叫智能体(agent)。智能体说,往右走,猫就向右移动一步。往右走往左走的行为,叫做动作(action)。猫具体在哪一个格子里面,称之为一个状态(state)。我们所有的事情都发生在这个图里面,这个图就称之为环境(environment)。强化学习的目的,就是让智能体告诉猫,通过最短的路径去走到目的地。
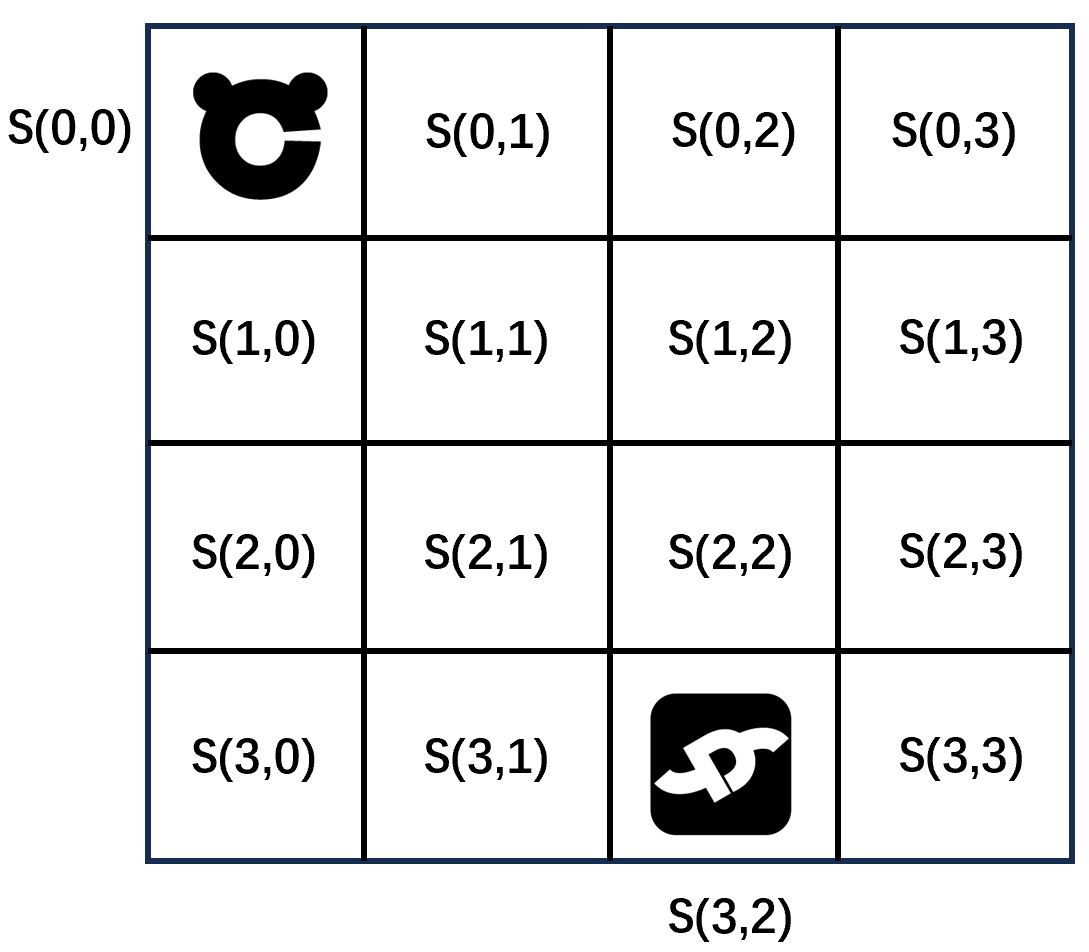
在上图中,猫可以存在16个格子里面,因此存在16个状态。我们对每个状态进行编号(如上图)。智能体告诉猫每动一次,状态就要变一下。在这个具体的算例里面,动作可以分为4种,也即上下左右。在下图中,猫在不同的位置,分别对应一个状态。
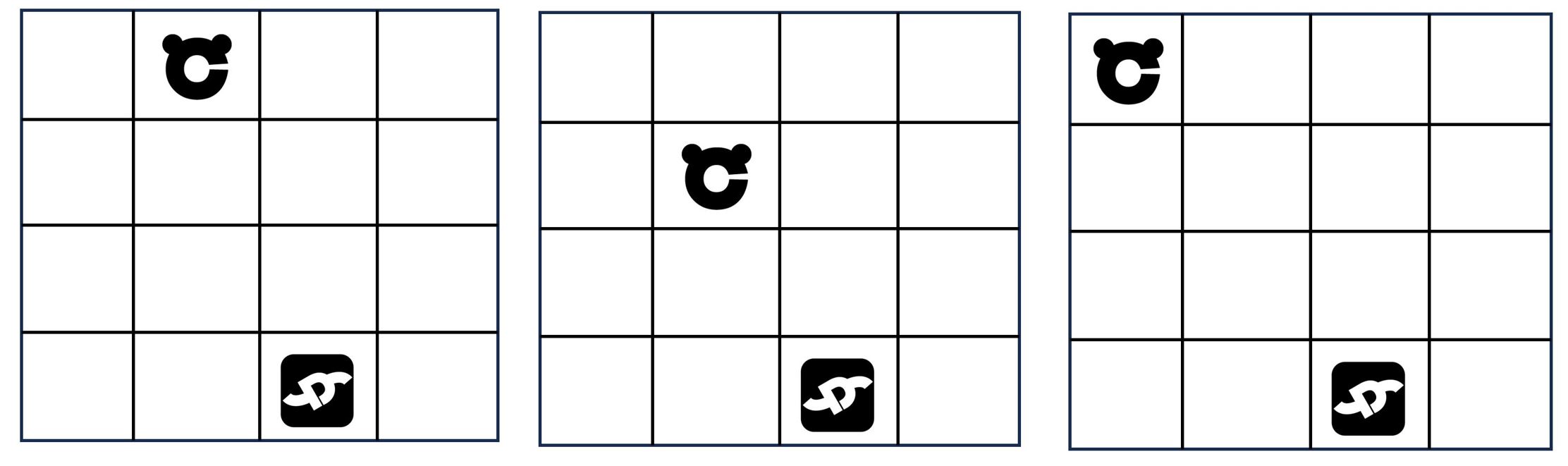
Q-learning算法的主要目的,就是创建一个表格,这个表格就是智能体。智能体告诉猫,在什么状态下,应该怎么走,才能通过最短的路径去达到终点。目前我们通过人脑可以看出,假设猫处于S(3,1)这个状态,就是终点左边的这个网格,猫需要往右走就可以到达终点,而不是往左走。那么我们最终的Q-learning创建的智能体(也就是这个表格),针对S(3,1)这个状态,可能的情况就是这样的:
状态 |
上 |
下 |
左 |
右 |
|---|---|---|---|---|
S(3,1) |
2 |
-1 |
4 |
12 |
我们来理解一下上面这个表格。针对 S(3,1)这个状态,存在4个动作,每个动作对应1个数字,其中最大的数字是12,这说明在这个状态下,往右走可以达到我们想要的效果。其实表中4个数字都是我拍脑袋写的,最重要的,是S(3,1)对应的向右的这个动作,数字要最大。Q-learning算法,就是要算出下面的这个类似的表格:
状态 |
上 |
下 |
左 |
右 |
|---|---|---|---|---|
S(0,0) |
max |
max |
||
S(0,1) |
max |
|||
S(0,2) |
max |
|||
S(0,3) |
max |
|||
S(1,0) |
max |
max |
||
S(1,1) |
max |
max |
||
S(1,2) |
max |
|||
S(1,3) |
max |
max |
||
S(2,0) |
max |
max |
||
S(2,1) |
max |
max |
||
S(2,2) |
max |
|||
S(2,3) |
max |
max |
||
S(3,0) |
max |
|||
S(3,1) |
max |
|||
S(3,2) |
0 |
0 |
0 |
0 |
S(3,3) |
max |
注意:
上表中空余部分也是有值的。只不过max是最大值。其他的值没有写。
其中的max表示,Q-learning处理出来的数据,相应的max一定是最大值。比如对于S(0,0)这个状态(就是猫处于左上角的网格),往下走和往右走都对应的最优策略,因此动作“下”与动作“右”都对应max的值。在后面会看到Q-learning是一种迭代算法,在收敛的情况下,动作“下”与动作“右”一定都对应max的值。很明显,假定这个表出来之后,把猫放在任意一个状态,他都会遵循max对应的动作,找到最优路径达到终点。上表中的具体的数值,也即Q值。每个\(Q\)对应一个状态\(s\)和一个动作\(a\)。因此\(Q\)是一个关于\(s,a\)的函数,可以写成\(Q(s,a)\)。问题是,这面这个图标是通过人脑看出来的,如何通过计算机处理出这样一个表格?
手算Q-learning
我们的问题是让猫通过最短的路径到达终点。那么如何能用数学来描述这个问题。很简单,我们可以把每一次动作想象成对应一个负数,每一次动作的进行,这个负数越来越大。到达路径的负数进行叠加,最大的负数对应最优的路径。比如我们定义每一次移动,对应-1,如果移动5次到达终点,那么总数就是-5。如果移动10次到达终点,那么综述就是-10。很明显,-5对应的路径就要比-10对应的路径好的多。

在上图中,我们把每个网格点标志了一个数字。比如从S(0,0)网格点移动到S(0,1)网格点,对应的数字是-1,那么我们就认为:猫从S(0,0)网格点,执行了向右的动作,移动到S(0,1)网格点,拿到一个数是-1。这个-1,就是奖励。同理,如果从S(3,1)移动到S(3,2),会发现这一次的奖励为10。
需要注意的是,其中具体的数字,比如是-1,还是-3,这完全是用户给定的。之所以我们给了一个负数,是因为我们的目的是告诉智能体,每多执行一次动作,都会带来一个负的奖励。之所以在终点是一个正的奖励,就是告诉智能体,如果移动到终点,那么可以大幅度的增加奖励的数值(其实也不需要是10,只要是比-1大的数就可以)。那么如何判断什么是最优路径,就是所有的动作带来的奖励的加和,对应的总值如果最大。那就是最优路径。这个所有的动作带来的奖励的加和,被称之为回报。针对这个算例,最优路径的寻找,变成了回报最大化路径的寻找的数学问题。
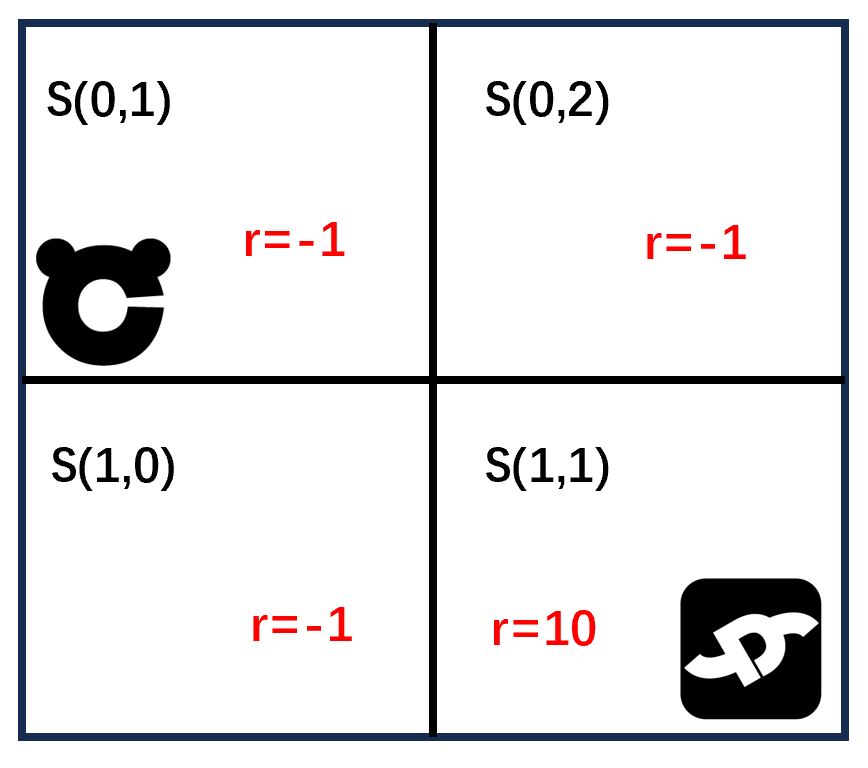
4\(\times\)4网格的算法对于计算机轻而易举,但是如果手算得话还是复杂了点。因此在这里用一个2\(\times\)2网格来进行一个真正的Q-learning算法的计算。
其中\(Q(s, a)\)表示当前状态\(s\),进行\(a\)动作的初始\(Q\)值,\(\alpha\)表示学习率,是一个超参数,也即自定义参数,在这里假定是0.1,\(r\)表示当前状态\(s\),进行\(a\)动作达到的奖励值,\(\gamma \)表示折扣因子,是个超参数,假定为0.9,\(q_{new}^{max}\)表示下一个状态下各种可能性动作可能带来的最大\(Q\)值。把自定义参数替换进去有:
假定我们的初始化\(Q\)表为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0 |
S(0,1) |
0 |
0 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
当前的状态在S(0,0),假定我们的给定的动作是“右”(这里面涉及到另外一个知识叫做\(\epsilon\)-greedy策略,将在后面介绍),我们可以来计算一下\(Q\)值:
因为初始的表中\(Q\)均为0,因此上式可以写为:
在这种情况下,\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.1 |
S(0,1) |
0 |
0 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
下面进行第二次更新。假定我们的给定的动作是“下”,来计算一下\(Q\)值:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.1 |
S(0,1) |
0 |
1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
目前的状态下,我们的猫走到了终点。现在进入下一轮的学习,回到S(0,0),假定我们的给定的动作还是“右”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.1 |
S(0,1) |
0 |
1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
随后假定我们的给定的动作是“下”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.1 |
S(0,1) |
0 |
1.9 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
进入下一轮的学习,回到S(0,0),假定我们的给定的动作还是“右”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.019 |
S(0,1) |
0 |
1.9 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
随后假定我们的给定的动作是“下”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
-0.019 |
S(0,1) |
0 |
2.71 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
进入下一轮的学习,回到S(0,0),假定我们的给定的动作还是“右”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.1268 |
S(0,1) |
0 |
2.71 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
随后假定我们的给定的动作是“下”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.1268 |
S(0,1) |
0 |
3.439 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
进入下一轮的学习,回到S(0,0),假定我们的给定的动作还是“右”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.32363 |
S(0,1) |
0 |
3.439 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
随后假定我们的给定的动作是“下”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.32363 |
S(0,1) |
0 |
4.1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
进入下一轮的学习,回到S(0,0),假定我们的给定的动作还是“右”,来计算一下\(Q\)值:
\(Q\)表更新为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.56 |
S(0,1) |
0 |
4.1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
至此,我们不再往下迭代。总结几点规律:
如果一直按照先往右,往下的策略进行计算,S(0,1)状态下,动作“下”的\(Q\)值会越来越大(越来越接近10)。这也就表明了,如果猫处于状态S(0,1)的网格,往下走才是最优策略;
针对S(0,0)也一样,向右走的\(Q\)值会越来越大,表明猫处于状态S(0,1)的网格,往右走才是最优策略;
表格中S(0,0)对应的向下走的动作为0,但是如果先向下走再想右走,同样也是最优策略。但是表格没有体现;
针对第三个情况,可以进行类似的先向下,再向右的迭代。比如进行几次迭代后,可能的\(Q\)表会变为:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0.56 |
0 |
0.56 |
S(0,1) |
0 |
4.1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
4.1 |
S(1,1) |
0 |
0 |
0 |
0 |
对于上述的\(Q\)表,表示当猫处于S(0,0),向下与向右都可以达到最优的策略。然而问题再一次出现,猫是否可能会从S(0,0)向右走到S(0,1),然后向左走回到S(0,0)呢?

Q-learning表
最终Q-learning针对每个状态下的动作,都有形成上图这样的一个基于Q值的东西。猫在每个状态下,选取最优的Q值对应的动作进行行动,可以获得最短路径。另外一种是给定每个状态一种值,而不是每个状态下的状态-动作的值。这将在文末最后介绍。
同策略与异策略
策略(policy): 猫会依据策略,来决定向哪个方向来走。如果完全是随机的,那么就是随机性策略(stochastic policy)。
系统的讨论策略之前,先看一下\(\epsilon\)-greedy策略。在上面的迭代过程中,猫向哪个方向都都是我拍脑袋指定的。在计算机层面,其原理很简单。假定给定某一步迭代好的Q表如下:
状态 |
Up |
Down |
Left |
Right |
|---|---|---|---|---|
S(0,0) |
0 |
0 |
0 |
0.56 |
S(0,1) |
0 |
4.1 |
0 |
0 |
S(1,0) |
0 |
0 |
0 |
0 |
S(1,1) |
0 |
0 |
0 |
0 |
在使用\(\epsilon\)-greedy策略的时候,首先通过计算机生成一个0与1之间的随机数\(R\),同时用户给定一个超参数\(\epsilon\),S(0,0)状态的猫是向右走还是向下走,取决于\(R\)与\(\epsilon\)的大小。如果\(R<\epsilon\),则随机选择一个动作。反之,则选择当前层面Q值最大的动作。在强化学习领域,随机的动作被称之为探索(exploration)。选择当前层面Q值最大而进行移动被称之为利用(exploitation)。探索过程是非常重要的,否则Q-learning可能会在自认为寻找到一个最优路线之后,而放弃寻找其他的最优路线。
同时\(\epsilon\)-greedy策略可以看做是\(\epsilon\)策略与greedy策略的混合。greedy策略意味着完全的利用,不具有任何的随机性。\(\epsilon\)策略意味着随机的探索。现在来看一下Q-learning更新Q表情况下使用了什么策略。回到Q-learning的Q值更新公式:
很明显,因为\(q_{new}^{max}\)表示下一个状态下各种可能性动作可能带来的最大\(Q\)值,因此是一种greedy策略,而不是\(\epsilon\)-greedy策略(完全没有随机性)。同时在更新Q值的时候,也使用了\(\epsilon\)-greedy策略决定下一步的动作。这种使用了不同策略的方法,叫做异策略方法(Off-policy)。
现在讨论另外一种方法:SARSA方法(State-Action-Reward-State-Action)。其与Q-learning非常类似。在SARSA中,Q值的计算方法与Q-learning相同,只不过其中的\(q_{new}^{max}\),在Q-learning是下一步最大的可能性的动作。但是在SARSA方法中,如果使用\(\epsilon\)-greedy策略,那么\(q_{new}^{max}\)对应的动作选择,还是通过\(\epsilon\)-greedy策略来确定。因此在SARSA方法中,一直使用的都是\(\epsilon\)-greedy策略。这种使用相同策略的方法,叫做同策略方法(On-policy)。
回头来看,什么是强化学习,在本文讨论的这个非常基础的案例上可以看出,强化学习就是让计算机自身去迭代,自己去寻找出最优路线的过程。这个迭代的过程即为学习。然而在目前这个阶段,完全没有涉及到神经网络。确实,Q-learning过程并不需要神经网络。然而我们可以在Q-learning的基础上,附加神经网络来处理更加复杂的情况。
最后,Q-learning算法通过Q值来决定最优的路线。还有一类方法是依据策略来进行最优路线的选取,在这种方法中不需要计算Q值。这将在其他章节介绍。
Deep Q-learning
Deep Q-learning (DQN)也被称之为深度Q网络。在上文讨论的原生Q-learning算法中,输入是一个状态,智能体会从Q表中查找出来最优的动作去执行。如果对于一个非常复杂的状态(比如一个10000\(\times\)10000的网格),以及很多可能性的动作(比如100个动作),这个表格将是非常巨大的(10000\(\times\)10000\(\times\)100)。另外,如果状态是连续的变化,Q表也不太行得通。深度Q网络就是把传统的Q表格,通过神经网络来进行替换。其输入一个复杂的状态,会输出一个最优的动作。只不过不是查表来进行,而是通过神经网络来进行。
类似其他深度学习技术,最早的深度Q网络也被用在了玩游戏上。2013年Google的deepMind团队Minh等将深度Q网络首发在arxiv上[MKS+13],截止到2024年引用15000次。2015年,深度Q网络技术细节刊发在Nature,截止到2024年引用30000次[MKS+15]。在深度Q网络主要解决了一系列的问题:
上文讨论的Q-learning算法,对于复杂的状态,以及可能得动作,这个表格极为庞大,基本不可用;
一个状态,可能并不存在最优的Q值。比如在Minh等玩的Atari电脑射击中,给定一个状态,可能不移动或者向右向左移动,都没有太大的关系。而是持续的移动5步并且进行射击的动作,才能算是赢得奖励;
为了解决第1个问题,作者们等使用卷积神经网络来处理这个问题。为了解决第2个问题,作者们引用了累计奖励、时间序列方法等来处理。
在Q-learning中,针对每个状态与动作,都可以通过查表的方式来查询最优的Q值。在DQN中,给定一套神经网络,则需要输入一个状态,DQN会给出每个动作对应的Q值(Q值最高的为最优动作)。所以DQN的输入层为状态,输出层为每个动作的Q值。类似其他神经网络,DQN需要定义一个损失函数。再次回到Q-learning的公式:

可以看出,\(Q_{new}(s, a)\)主要就是通过这一步动作的奖励以及下一步动作可能得做大奖励,来更新当前动作的Q值。另一方面,方程(16)似乎可以这样写:
其中\(r +\gamma q_{new}^{max}-Q(s, a)\)可以看成一个修正,其中的学习率,类似CFD中的亚松弛因子。就是每一次的修正的\(Q_{new}(s, a)\)相对于\(Q(s, a)\)不要一次变动的太大。传统Q-learning在训练的过程中,这个修正会逐渐减小,也就是最终\(Q_{new}(s, a)\)的值会稳定不变。也就是这个修正会趋向于0。
现在单独看这个修正\(r +\gamma q_{new}^{max}-Q(s, a)\)。既然希望修正越来越小,那就是:
改写方程(19):
其中的\(y_{s,a}-Q(s, a) \)就可以用来构建损失(比如均方差)。
最优状态值、Bellman方程
回到猫找出口的这个算例。现在来看一下另外一种方法。类似Q-learning,这种方法也是基于一种值的(在这个链接中,将介绍基于策略的方法)。这种方法更简单,但貌似用起来比较少。下面对其进行介绍。
参考下图中的右图,最优状态值方法最终会在每个状态下,返回一个值V。猫在移动的过程中,策略可以选用贪婪策略,这样就可以最快的到达终点。比如猫在右上角的情况下,往左走的V值是-3,往下走的V值是-1,贪婪策略告诉猫,一定是向下走获得最优路径。因此最优状态值方法的核心问题是如何获得这些V值。这可以通过迭代的方式来进行。

可以最初将4个V值初始化为(通常终点的\(V_{11}\)直接给定奖励值)
认为V的迭代可以通过下面的方程来进行(采用完全的贪婪策略,体现在其中的\(\max\)函数):
假定\(\gamma=1\)。例如对于\(V_{00}\),其可以向下,也可以向右移动,因此:
例如对于\(V_{01}\),其可以向左,也可以向下移动,因此:
同理,对于\(V_{10}\)以及\(V_{11}\)(不需要移动):
因此第一轮迭代后有:
如果我们继续进行迭代,有:
继续进行迭代,值不会发生变化。因此最终的值即为
有了最终的V值之后,猫移动的过程中会选择最大的V值来进行移动,这样可以获得最优路线。可见,最优状态值方法与Q-learning稍有不同。其对每个状态给定一个V值,而不是每个状态-动作对一个值。
其实方程(20),如果不考虑其中的\(\max\)函数(\(\max\)函数只不过是我们使用了贪婪策略),就是Bellman方程。在最优状态值方法中,其表示当前的V值,取悦于依据某种策略进行的动作后获得的奖励,与下一个状态对应的V值乘上一个折扣因子之和。更简单的理解,就是当前的V值,取决于执行动作后下一个状态的V值。
Q-learning以及最优状态值方法,都是基于值的方法,也即Value-based method。
蒙特卡洛与时间序列
方程(20)中仅仅涉及到了折扣因子。并没有涉及到学习率。这里面牵涉到是否是无模型(model free)的问题。model free目前不做介绍。回头来看会更简单。
如果将其改写为:
其中的\(G\)表示从s状态,一直走到终点的总共的奖励。其次,\(G\)涉及到一系列的状态。其中在某一步具体采取什么动作,可以采取贪婪策略,也可以采取epsilon-贪婪策略等各种策略。不管采取什么策略,方程(21)需要走到终点,才能计算从s状态到终点的\(V_{s}\)。若要计算另外一个s的状态,可以依据方程(21)来计算。这种方法被称之为蒙特卡洛方法。
方程(21)可以继续改写,如:
方程(22)与方程(21)的区别主要是\(\underline{r_{s+1}+\gamma V_{s+1}}\)。在蒙特卡洛方法中,奖励是总奖励\(G\),在方程(22)中,奖励是\(r_{s+1}+\gamma V_{s+1}\)。这种方法的思想就是时间序列方法。在时间序列方法中,每采取一个动作,都可以更新一次V值。然而在蒙特卡洛方法中,需要走到终点后,才能更新V值。
同时,\(\underline{r_{s+1}+\gamma V_{s+1}}\)被称之为时间序列的目标,\(\underline{r_{s+1}+\gamma V_{s+1}} -V_{s}\)被称之为时间序列的误差。可以发现,方程(17)其实就是时间序列的误差。也正因为如此,时间序列的误差可以认为是对当前V值的一种修正。
时间序列方法可以理解为把当前的奖励\(r_{s+1}\),与未来一步可能的折扣奖励\(\gamma V_{s+1}\)之和\(r_{s+1}+\gamma V_{s+1}\),当成总奖励\(G\)。这种方法也即bootstrapping。
到目前这一步,回头看Q-learning方程(1),可以发现其其实也使用了时间序列的方法。
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, and others. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.