版本对应:
本网页讨论的机器学习内容,为特定的机器学习内容(并未与CFD结合)。在《无痛苦NS方程笔记》中, 特定的将CFD与机器学习互相结合起来,无普适性机器学习内容。
ML: 残差神经网络
ML: 卷积神经网络中我们提到了卷积神经网络通常使用多个卷积层。即使在全连接网络下,有些情况可能网络也包含了大量的隐藏层数。在这种情况会产生一些问题。在下图中[HZRS16],可以看出在使用56层的时候,误差明细要比20层要高得多。这也被称之为退化问题。

仔细看一下深层神经网络的设计可能会发现更多的问题。先看第一个问题,设想一个20层的神经网络,因为初始的情况下,神经元的权重都是随机设定的比较小的数。加入输入层输入一套数据,经过第一层后,原始数据需要跟随机权重进行数学运算,经过第二层后,原始数据还需要跟随机权重进行数学运算。问题是经过太多层之后,原始数据的信息被初始的随机权重彻底的被打乱。到最后一层的时候,原始数据基本就成了随机的噪声。这样来训练神经网络的效率是非常低的,损失会很难下降,因为很难获取到输入的信息。
第二个问题,假设计算出来损失后,即可以计算梯度。参考ML: 手算反向传播与自动微分,梯度在向后传播的时候需要乘以权重。同样因为权重都是比较小的数。会导致梯度逐渐的变小。如果层数越多,计算的梯度就会越小,也即梯度消失。
残差神经网络的设计理念非常简单,且易于实施。同时具备简单、高效、且能解决实际问题,这应该也是残差神经网络距今被引用超过22万次的一个原因[HZRS16]。残差神经网络的设计理念认为,对于深层网络,想要达到与浅层网络一样的效果,是不是可以想一种办法,把其中某些层的作用去掉?举个例子,一共100层的网络,如果后面90层什么作用都不起,这是不是就等于是一种浅层网络?
下图可以更明确的讨论残差神经网络的设计理念。神经网络的每一层的输入\(x\),其都会与权重相结合,变成\(x\)的输出。假定第一层输入是\(x_1\),第二层输出是\(x_2\),那么第100层输出就是\(x_{100}\)。残差神经网络希望\(x_{10}=x_{100}\)。这在常规神经网络设计中是无法做到的。因为如果把后面90的权重处理为0。那么这些层的输入就会全部都是0。这很明显是不正确的。然而在下图的设计中,假设红框内的2层使我们想忽略的层,我们可以直接把红框的输出,设定为\(F(x)+x\),在这种情况下,如果\(F(x)\)全部为0也没有关系,其输出也为\(x\)。
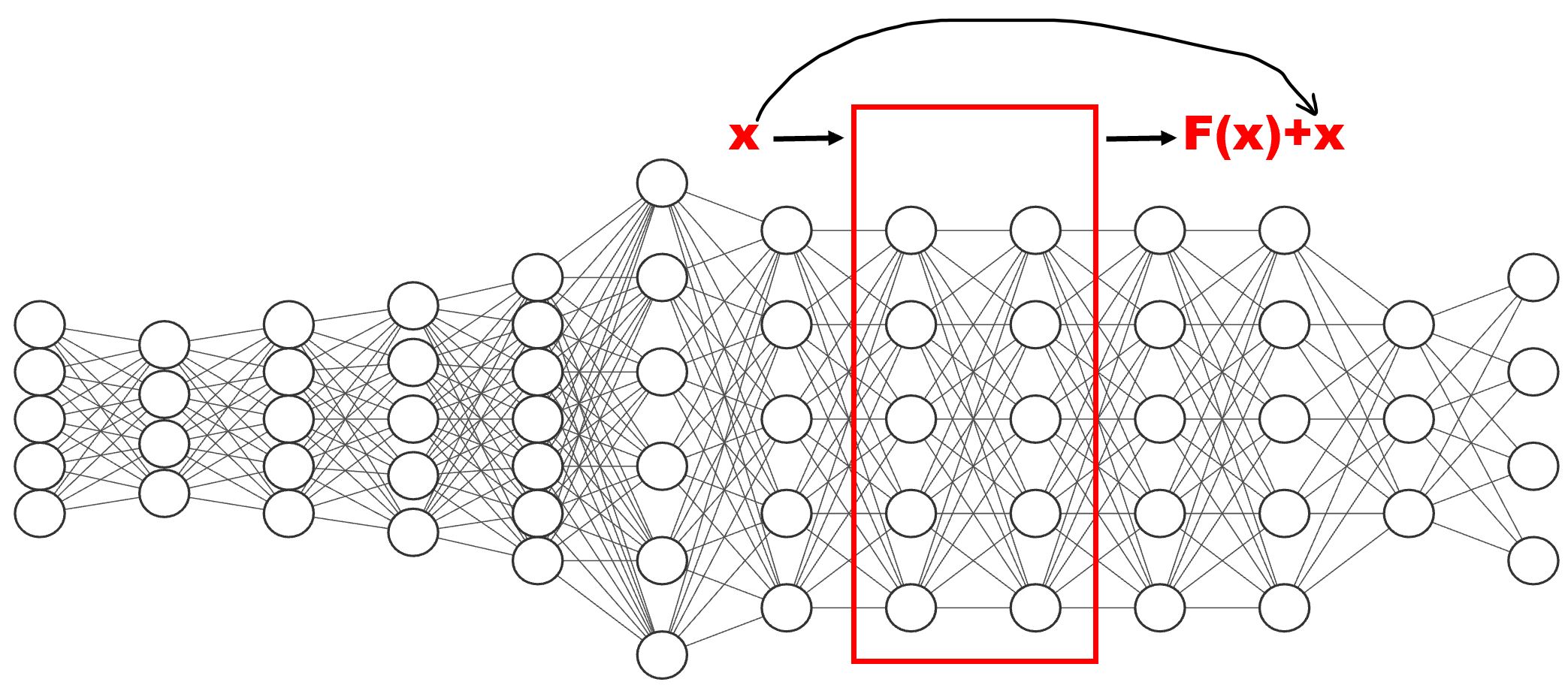
上图上的黑线,也被称之为跳跃连接(skip connection)。红线的输入层\(x\),如果与输出\(F(x)+x\)相等的话,就表明\(F(x)=0\)。\(F(x)\)也可以理解为\((F(x)+x)-x\)。\(F(x)+x\)可以认为是真实解,\(x\)可以认为是初始解。那么\((F(x)+x)-x\),也就是\(F(x)\)就可以理解为残差。那么这个红框,就可以理解为残差块。
在实际操作过程中,红框里面可能具有不同的神经元数量,这会导致\(F(x)\)与\(x\)无法相加。这样可以在\(x\)上填充0即可。
下面手算一些为什么残差神经网络的梯度不会消失。ML: 手算反向传播与自动微分有方程:
其仅仅调用了2层神经元,如果具有5层神经元,则损失的导数可以变为:
其中\(\frac{\p y_{iter}}{\p a_4},\frac{\p a_4}{\p a_3},\frac{\p a_3}{\p a_2},\frac{\p a_2}{\p a_1} \)均表示相应的权重。在层数越多的情况下,这些权重的乘积越小,越容易出现梯度消失的情况。考虑比较简单的情况,假定每一层都增加一个跳跃连接,也即每一层的输出都\(+x\),其相应的导数则变为:
以此类推。因此,针对方程(1),其可以近似的写为:
方程(2)并不会出现梯度消失问题。同样也可以看出,如果相应的权重为0,那么这部分残差块就不会起任何作用。也即残差块的意义。